With the spread of event-driven architectures, the popularity of messaging platforms like Apache Kafka continues to grow. While performance of the middleware inevitably influences your system, throughput and latencies may vary under different conditions and configurations. Apache Kafka’s performance has been under evaluation by various vendors for almost 10 years now. However, the product evolves—as well as its competitors and the technologies it may be deployed on. Therefore, we decided to collect the most recent performance comparisons available. This article also contains benchmarks evaluating Apache Kafka on different cloud infrastructures/platforms.
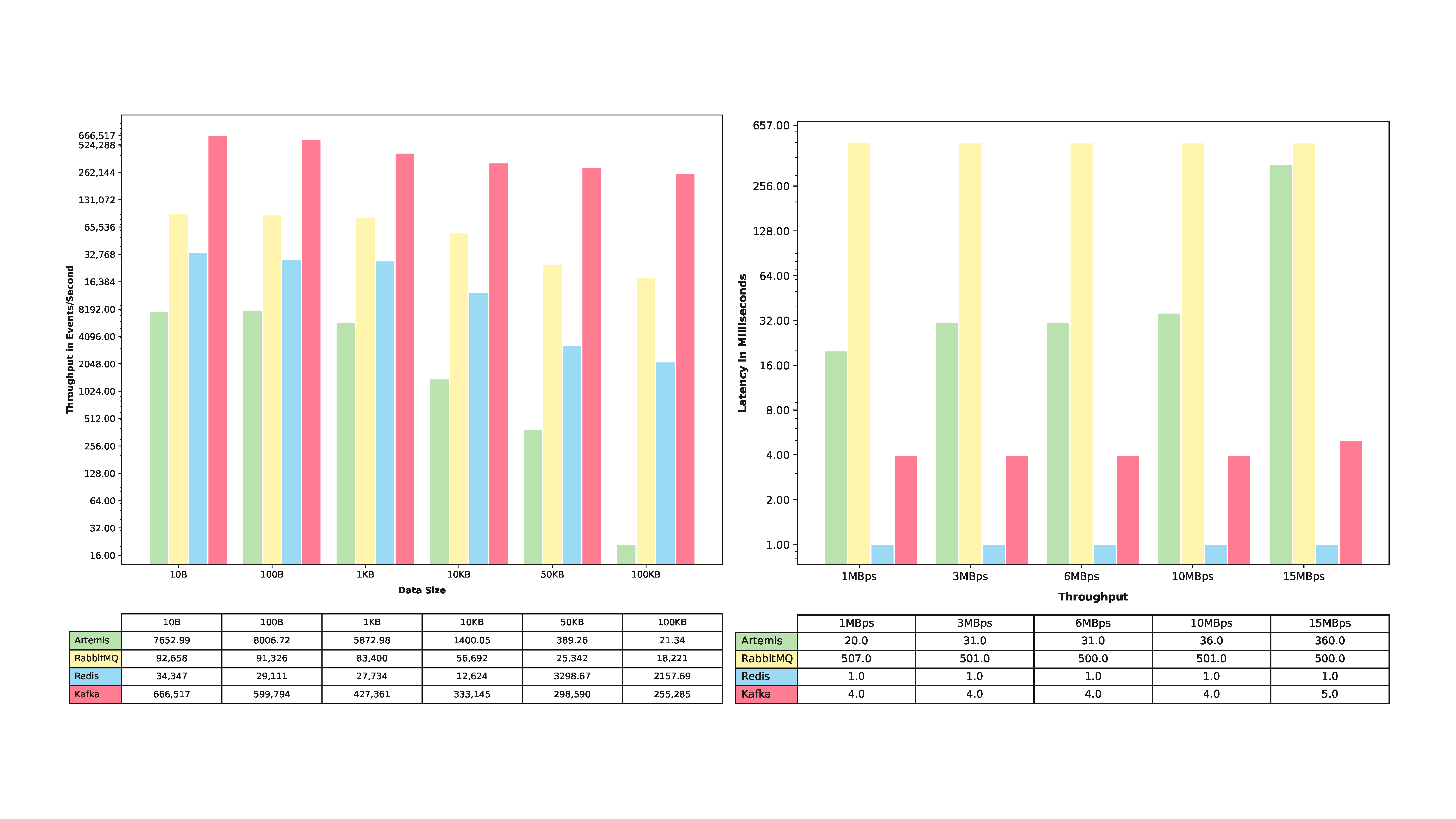
In June 2023, computer science researchers at Baylor University measured the throughput and latency of these four dissimilar yet popular products. The study utilized the OpenMessaging Benchmark Framework.
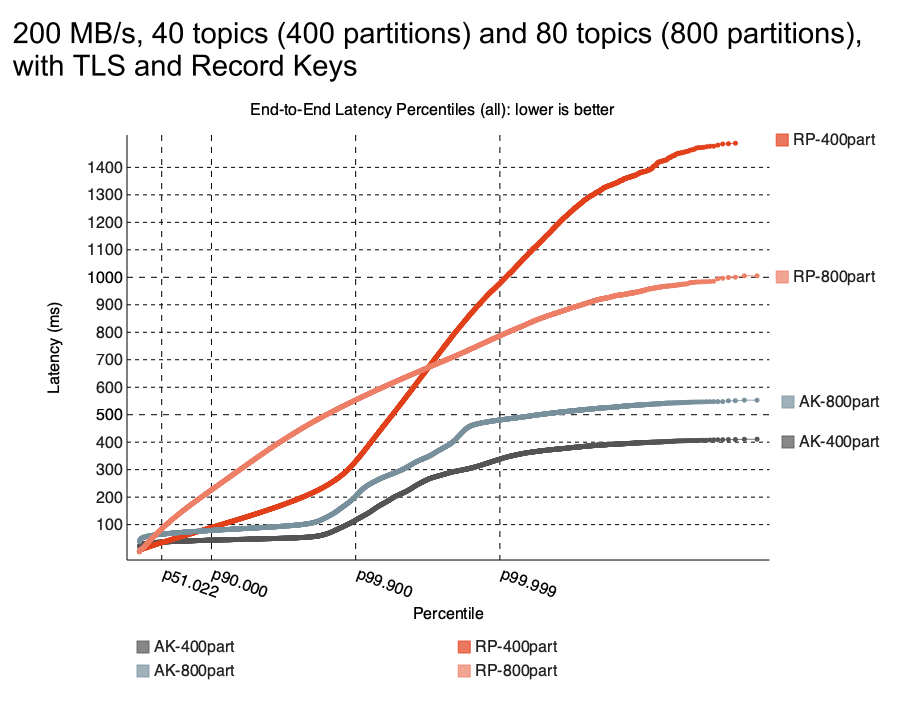
While in October 2022 Redpanda published a benchmark comparing its product to Apache Kafka, an engineer from Confluent aimed to reproduce the results in March–May 2023. During independent and very detailed evaluation with 3 brokers on i3en.6xlarge, Jack Vanlightly found completely different results. The blog series contains a lot of insightful notes on what needs to be done to properly analyze the two products and provides a thoughtful analysis of the results.
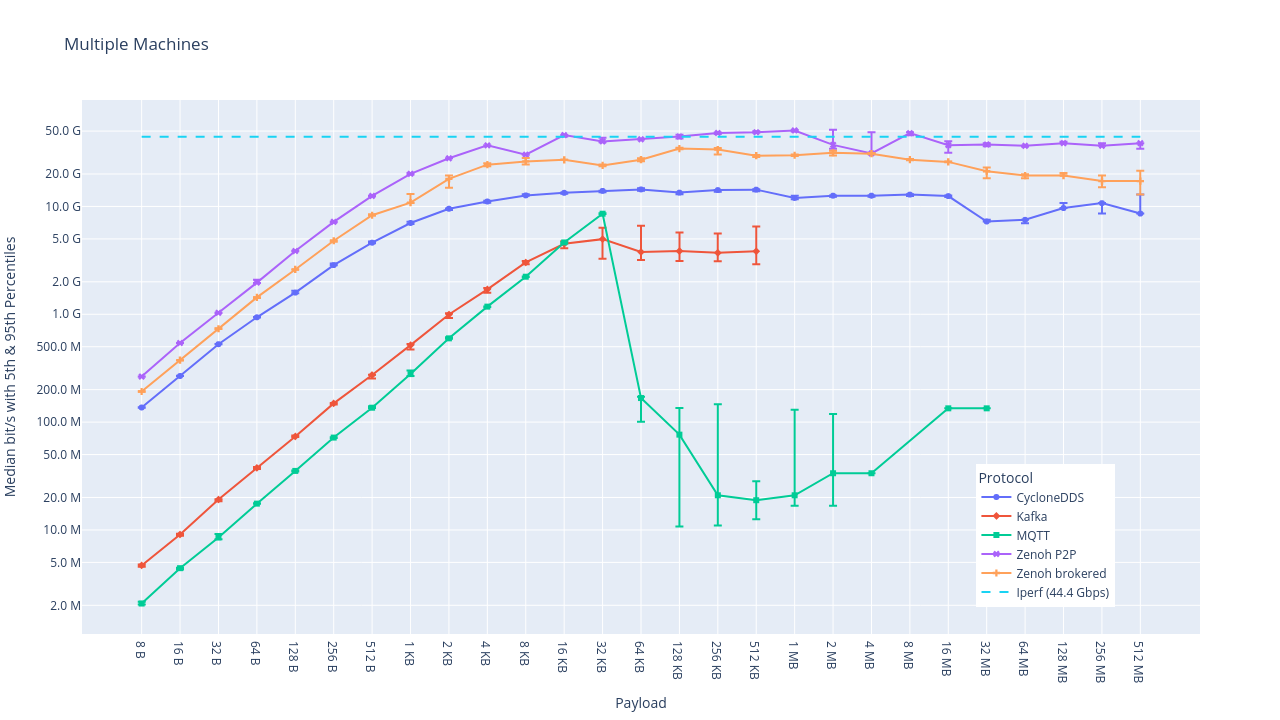
In March 2023, researchers from the National Taiwan University tested four popular messaging solutions (see the blog post and the paper). The experiment encompassed two scenarios: one was run on a single machine, and the other used multiple servers connected via Ethernet. For the throughput benchmark, payload sizes varied from 8 bytes to 512 MiB, while latency was tested with the payload fixed at 64 bytes.
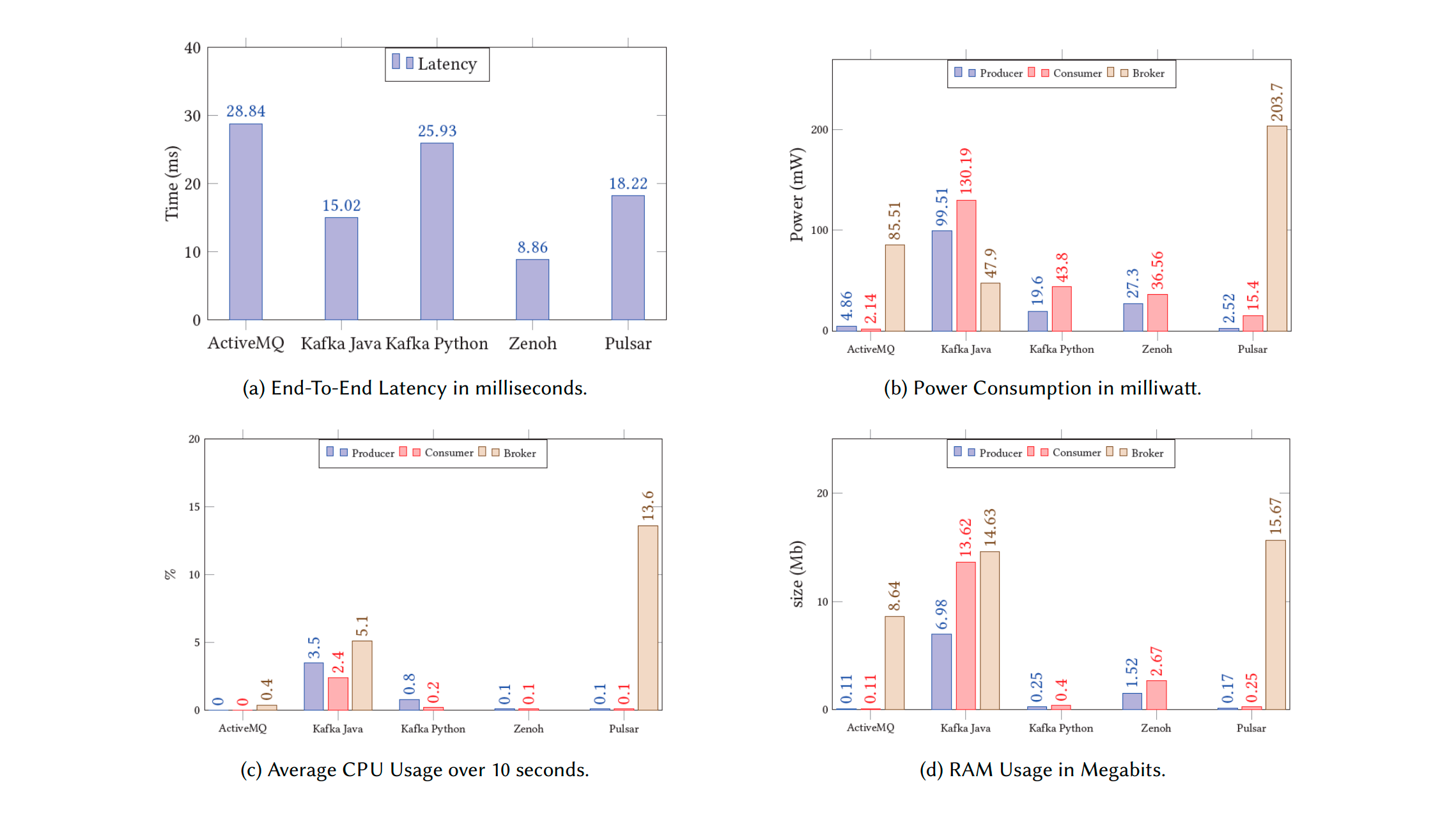
Researchers from the University of Antwerp ran this comparison in September 2022. The benchmark used a fixed RSU, which communicated with a mobile OBU over 4G with a payload size of 256 bytes.
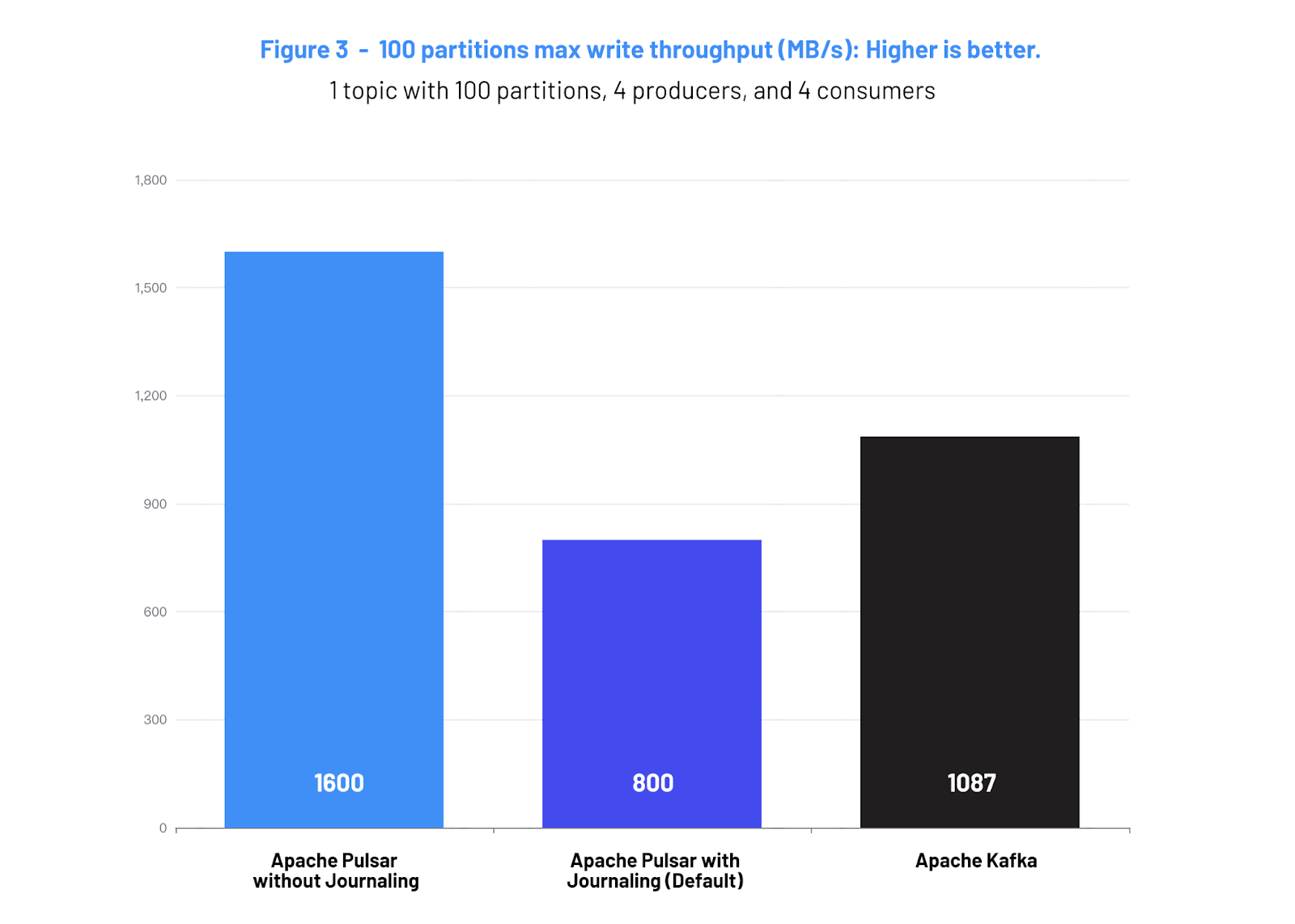
In April 2022, StreamNative—a developer of a cloud-based streaming data platform powered by Apache Pulsar—published another performance benchmark. Comparing Pulsar v2.9.1 against Kafka v3.0.0, the tests evaluated Apache Pulsar with and without journaling.
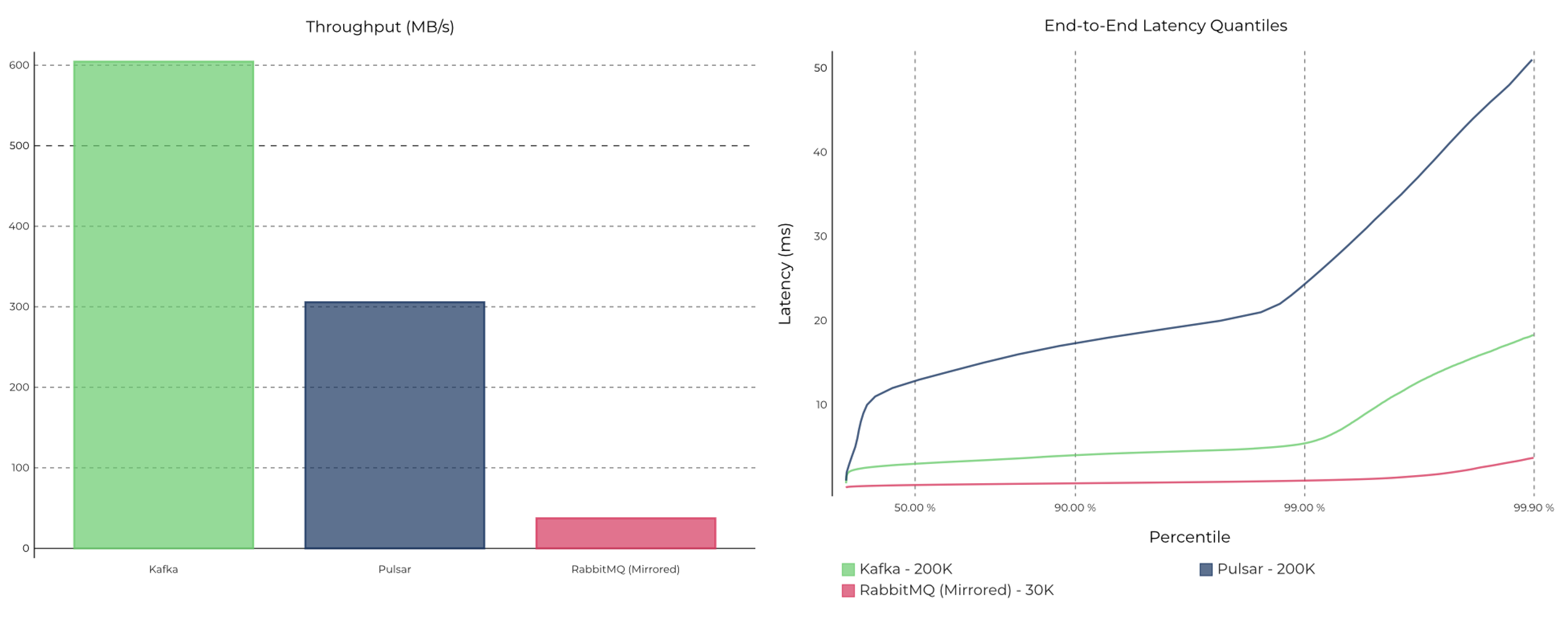
In July–August 2020, Confluent—a company behind a cloud-native data streaming platform—conducted a benchmark between Apache Kafka, Apache Pulsar, and RabbitMQ. The tests used three Amazon EC2 i3en.2xlarge instances for the producer, broker, and consumer.
Other performance benchmarks that compare Apache Kafka to its alternatives:
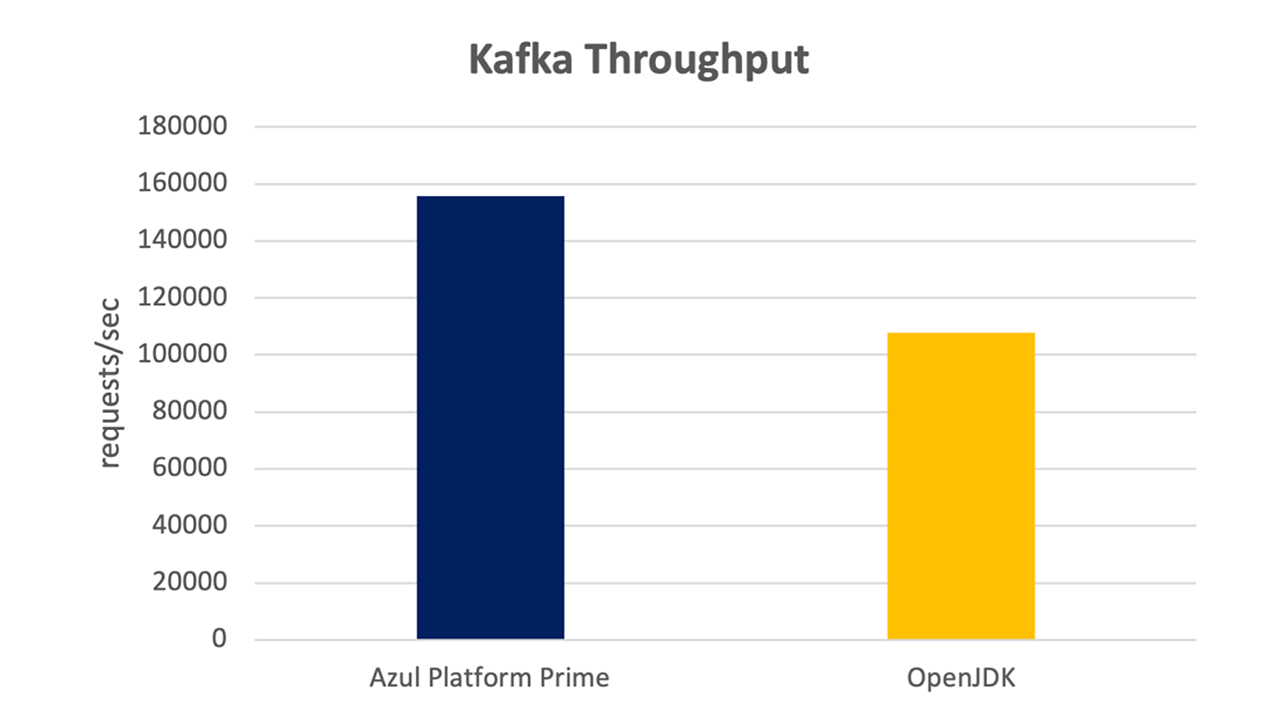
In July 2023, Azul conducted a benchmark that compared Apache Kafka running on Azul Platform Prime JVM vs. OpenJDK. The tests were conducted with three Kafka broker nodes and one node for Zookeeper. The experiments revealed that disk speed and choice of the filesystem influence Kafka performance significantly.
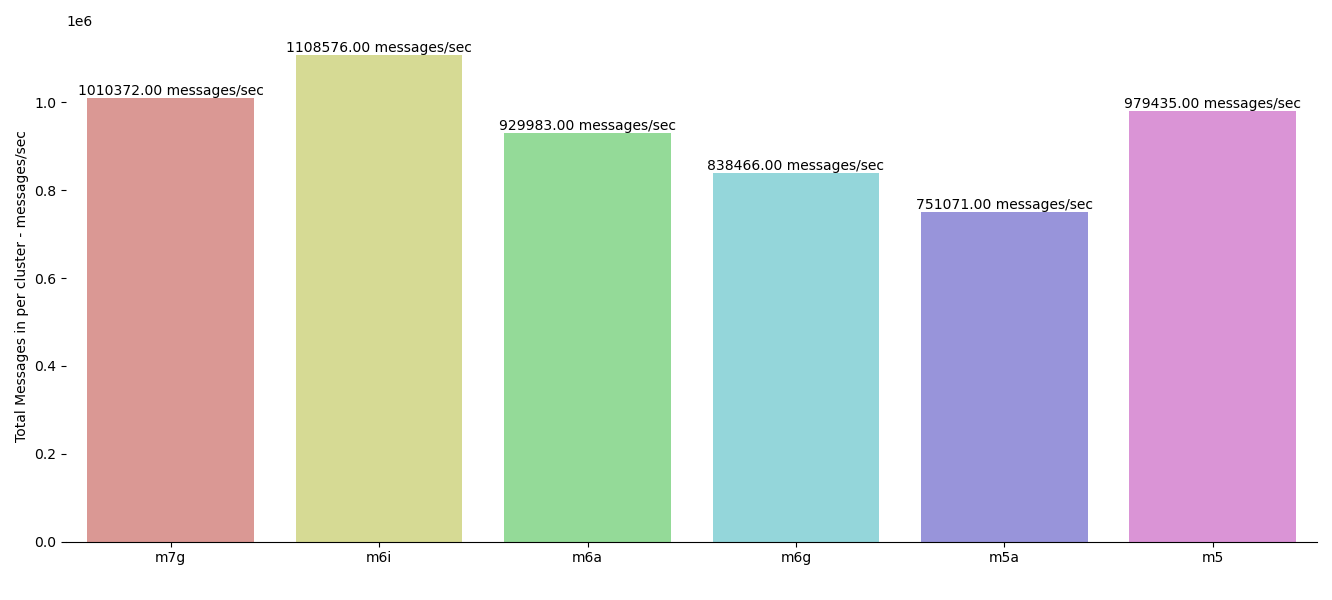
In May 2023, Aiven benchmarked Kafka v3.3 on AWS Graviton v2/v3 processors against Intel- and AMD-powered instances. A 3-node Kafka cluster was run on 6 different architecture instances, evaluating performance, stability, as well as pricing per hour and per 1 billion messages.
In October 2021, the Instaclustr team issued a benchmark evaluating Apache Kafka on AWS Graviton2 instances, while exploring the benefits of using gp3 SSDs to boost performance. The study highlights what needs to be done to make this configuration work and how Amazon Corretto Crypto Provider (ACCP) helped during the process.
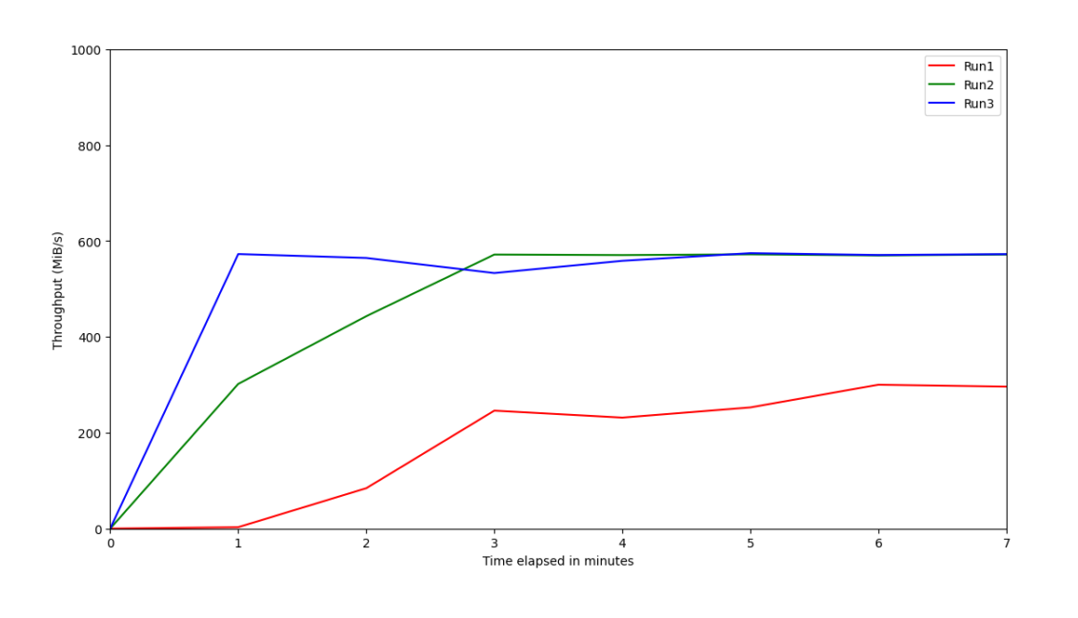
In July 2021, an architect from Red Hat evaluated the performance of Kafka v2.6 with Quarkus v1.11.1. He was using the AMQ Streams v1.6 distribution (Red Hat’s data streaming platform based on Kafka) on OpenShift Container Platform v4.5 (built upon Kubernetes). Rather than benchmarking the maximum performance, Berker Agir aimed to demonstrate how different configurations impact producer message throughput.
More performance benchmarks like that were issued by infrastructure vendors:
Benchmarks indicate that the performance of Apache Kafka may depend on the scenario, configuration, and the platform it is running. Thorough technology benchmarking can reveal unexpected behavior or give other insights vital to understanding how the evaluated tool fits the specific requirements of your project.
In addition to 20+ studies above, the performance reports below can also be helpful. Though they do not compare Kafka to other platforms, they reveal how performance can change under various requirements, implementations, and optimizations.
This collection of performance comparisons may not be exhaustive—new evaluations are being released almost each month. Therefore, if you know any other Apache Kafka benchmarks we missed—feel free to add them in the comments.
What is Apache Kafka?
Apache Kafka is a robust, open-source stream-processing platform that has revolutionized how companies process and analyze real-time data. Kafka uses a binary TCP-based protocol and is designed to handle data streams from multiple sources, delivering messages to multiple consumers with high performance and in real-time. Kafka was originally developed at LinkedIn in 2010 as a solution to improve the company's data pipelines. In 2011, Kafka was open-sourced as part of the Apache Software Foundation, making it available to a broader community.
In 2012, Kafka became a top-level Apache project, signifying its maturity and the community's confidence in its potential and stability. This milestone was crucial in cementing Kafka's reputation as a reliable and scalable choice for handling real-time data streams. The introduction of the Kafka Streams API in 2016 marked its evolution from a messaging queue to a full-fledged stream processing framework, enabling users to process their data directly within Kafka. This shift expanded Kafka's use cases beyond just messaging and into the realm of complex event processing and real-time analytics.
One of Kafka's most influential milestones came in 2017 with the introduction of exactly-once semantics. This made stream processing more reliable by ensuring that events are neither lost nor duplicated.
How does Apache Kafka differ from Pulsar and RabbitMQ?
Apache Kafka's architecture is fundamentally designed as a distributed commit log. At its core, it uses a broker system where each broker is responsible for storing data and serving clients. Kafka organizes messages into topics, and each topic is divided into partitions to ensure parallel processing and scalability. Producers publish messages to topics, and consumers subscribe to topics and process the feed of messages. Kafka maintains high performance and durability by replicating the partitions across multiple brokers and uses Zookeeper for broker coordination and maintaining the cluster state. Kafka's architecture excels in scenarios requiring high throughput and durability, making it ideal for building real-time streaming data pipelines and applications.
Apache Pulsar is recognized for its two-layered architecture, separating the serving layer (brokers) from the storage layer (BookKeeper). This distinct architecture allows for independent scaling of serving and storage resources, providing flexibility, and efficiency in resource utilization. Pulsar's brokers handle client connections and implement various messaging protocols, while the BookKeeper handles durable storage of messages. Similar to Kafka, Pulsar organizes messages into topics and partitions for scalability. However, Pulsar enhances its architecture with features like multi-tenancy and geo-replication out of the box. This allows for effective resource isolation and data synchronization across different clusters. Pulsar's architecture is often chosen for its cloud-native design, supporting real-time analytics and data integration in a multi-tenant environment.
RabbitMQ follows a more traditional message broker architecture with a focus on flexibility and reliability. It manages and routes messages through exchanges based on rules defined in bindings. Messages are then stored in queues until consumed by applications. RabbitMQ's architecture is focused on ensuring message delivery and providing various routing options. This makes it versatile for different messaging patterns. It supports multiple messaging protocols, such as AMQP, MQTT, and STOMP, offering a broad range of compatibility with different systems. RabbitMQ's architecture shines in scenarios that require complex routing, immediate message delivery, and a guarantee that messages are safely transferred.
How can the performance of Apache Kafka be optimized?
To improve Apache Kafka performance, consider balancing the number of partitions, optimal replication factors, adjusting broker topic configurations, optimizing producer settings like batch size and compression, etc. It is also important to fine-tune consumer fetch sizes and manage hardware resources efficiently.
Increasing the number of partitions enables more parallelism, thus also improving throughput. However, too many partitions can, vice versa, increase overhead and decrease performance.
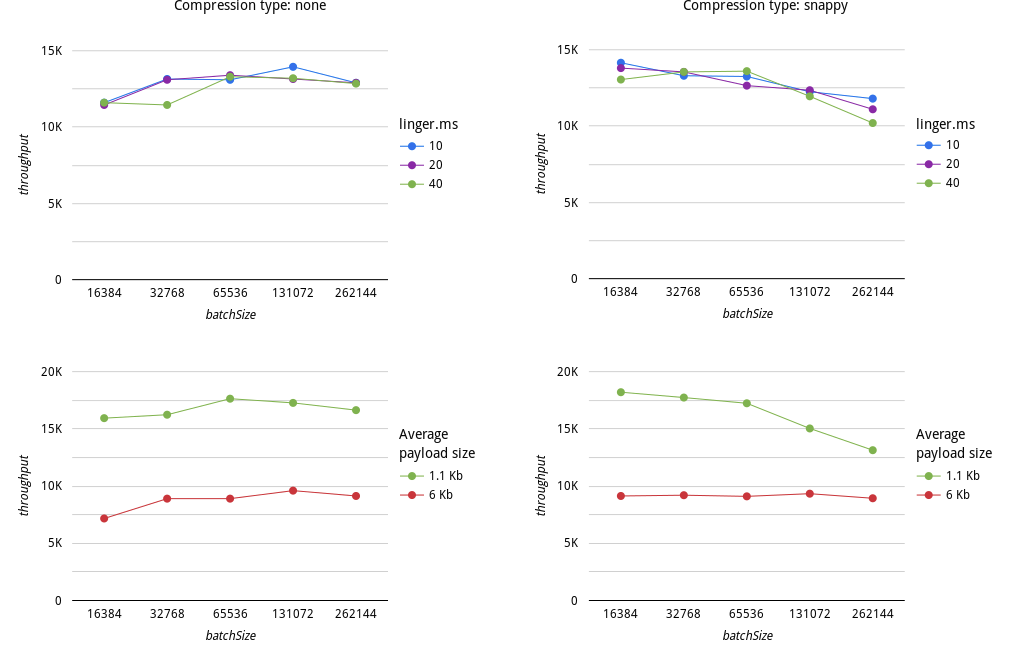
A guide by Microsoft details how to optimize Kafka on Azure by adjusting producer, broker, and consumer settings. Another tutorial (by HUMAN Security, Oct 2023) focuses on fine-tuning Kafka by changing compression types.
Other factors can also increase Kafka's throughput. SSDs, for example, can improve performance over HDDs due to their faster read/write speeds.
How much throughput can Apache Kafka handle?
The performance of Apache Kafka can be significantly high, but it's not a fixed number. The throughput depends on various factors—including hardware configuration, network setup, configuration, topic partitioning, message size, and the specific workload being run. Generally, Kafka is known for its ability to handle massive load scenarios.
Back in 2014, the LinkedIn Engineering blog revealed that Apache Kafka can handle more than 2 million records per second on three commodity machines. In 2022, this figure was eventually confirmed by Honeycomb for their real-life deployment, which uses the Confluent platform for the purpose.
How can one measure the performance of Apache Kafka?
If you are looking to conduct your own Apache Kafka performance tests, there are several tools that can be used for the process. For instance, the OpenMessaging benchmark by Confluent is one of the most popular tools used within the industry. Another application that can be used is JMeter—see the docs and read this guide from Blazemeter to learn how to test Apache Kafka with this product.
Developed by Grafana Labs, k6 is one more open-source load testing tool. This blog post details how to monitor Kafka producers and consumers. Another guide demonstrates how to determine the maximum load with Gatling.
Governed by LF and designed to shift data analytics closer to devices, this lightweight IoT…
What are the latencies and throughput of Mosquitto, VerneMQ, EMQX, NanoMQ, HiveMQ, RabbitMQ, FlashMQ, ActiveMQ,…
Aiming for operational improvements, manufacturers are struggling with system complexities. Is there a way out?
Supported by Dell, IOTA, Intel, etc., this open-source project assigns trust scores to sensor data,…
Google will sunset its IoT Core on August 16, 2023. Some of the edge devices…
For 53% of institutions, breaches in connected systems affect patients—e.g., lead to delayed surgeries or…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}